
Neighbourhood based classifiers
Contents
3.2. Neighbourhood based classifiers#
Tree based classifiers being not significant, we chose to apply algorithms based in neighbourhood and similarities to see if we can get more information for this pixel dataset.
3.2.1. K-Nearest Neighbours#
We tried to apply the K-Nearest Neighboors (KNN) algorithm which work on distance criterion in the space of the variables. From the train set, we choose an integer \(k\) corresponding to the number of neighbours we will consider to classify new data. Looking at the class of the \(k\) closer individuals to the new one in the space of variable, the algorithm predicts the class of the individual of the test set. The number of neighbour we choose to consider has an influence to the classification. Indeed, when \(k\) increases, range of neighbourhood increases too, leading to a prediction more global than precise.
After several combinations of parameters, we choose to set \(k = 5\), this value being the one giving the best results for this dataset. The Figure 3.10 shows the results of the cross validation on the 5 samples and the Figure 3.11 the confusion matrix and the projection of the test on CI06 with learning on the 4 other pictures. We can see that the prediction results are better than XGB without data balancing, but XGB with undersampling remain better. Apply undersampling or oversampling could have been done, but we chose to move on and try stronger tools (see Support Vector Machine).
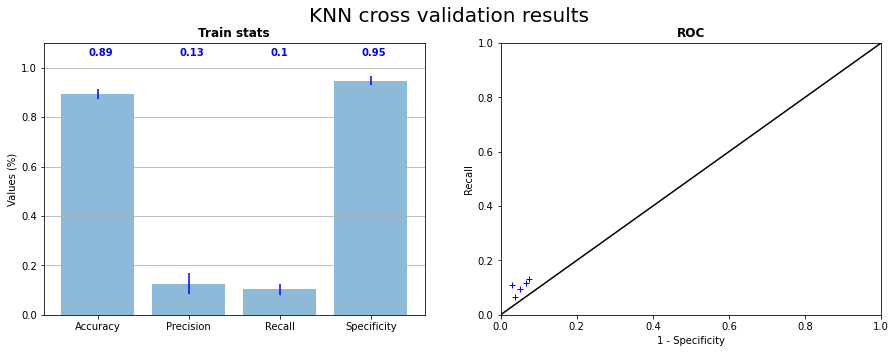

Fig. 3.10 KNN cross validation on the 5 samples statistics and corresponding ROC curve#
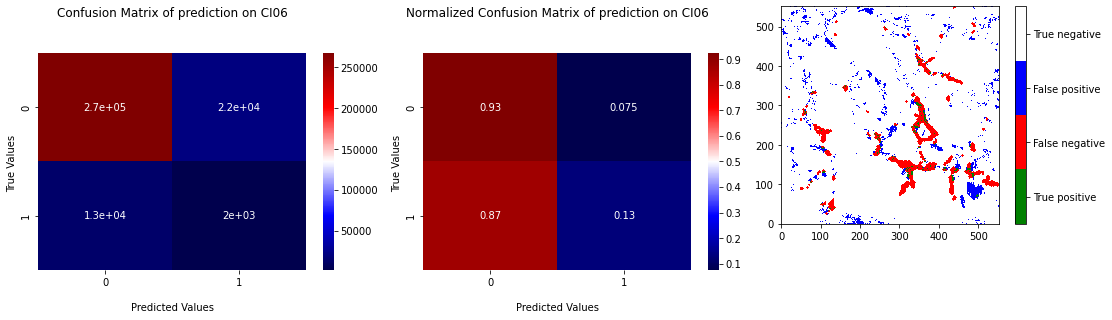
Fig. 3.11 Confusion matrix of prediction of KNN on CI06 with learning on 4 others samples with projection of the prediction.#
3.2.2. K-means#
First for a try, but finally with interest, I apply the clustering algorithm k-means to the pixel dataset. This method is usable as a binary classifier if we specify only 2 clusters to build. Associating after clustering the class with the best correspondences, we build a classifier which draws the limits of category by finding iteratively the best center of two categories in the variable space.
The similarity of the 2 classes has also an impact on the prediction of k-means. Indeed, the 2 center being closed, k-means has difficulties to distinguish the 2 categories without overlap the area of prediction. We can see in the Figure 3.12 that RX predictions of k-means are shaped as “blobs” around grain boundaries. This kind of prediction gives no more information that a method giving only zeros. On the Figure 3.13, we can observe on the ROC curve that points of the 5 tests are around the upper right corner, that signify that method have a tendance to predict too much 1. The recall is high but the specificity is low.
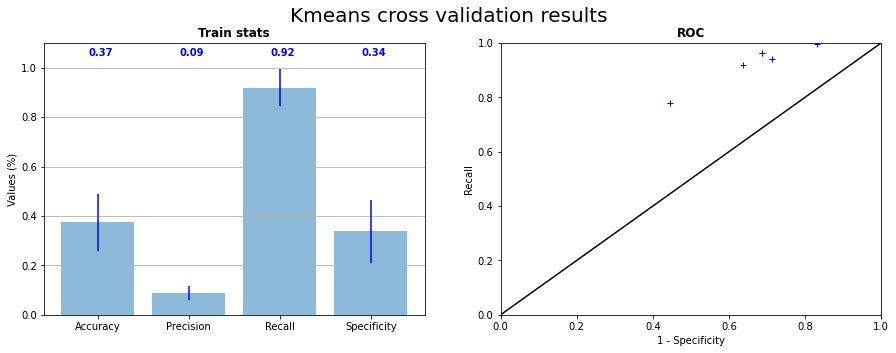
Fig. 3.12 K-means cross validation on the 5 samples statistics and corresponding ROC curve#
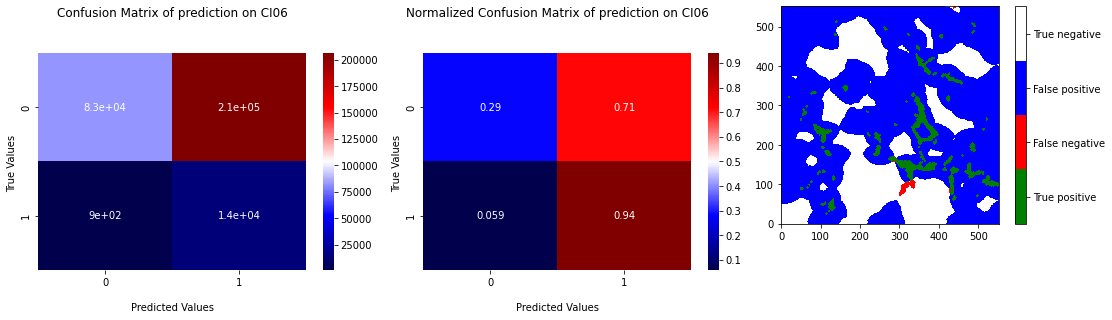
Fig. 3.13 Confusion matrix of prediction of k-means on CI06 with learning on 4 others samples with projection of the prediction.#
We tried to apply kmeans on the sub-dataset described section Pixel threshold to see if moving around the pixels too far from the grain boundaries has a significative effect. We can see in Figure 3.14 and Figure 3.15 the results of the cross validation with learning on the sub-datset. Points of test prediction on ROC curves are better placed with a mean recall at \(0.7\) and a mean specificity at \(0.66\). The majority of RX pixels are catched but the prediction still remains “blobs” around triple junctions. Looking at the ROC curve, this could be the best model for now, but the prediction gives no more information that RX points append close to triple junction.
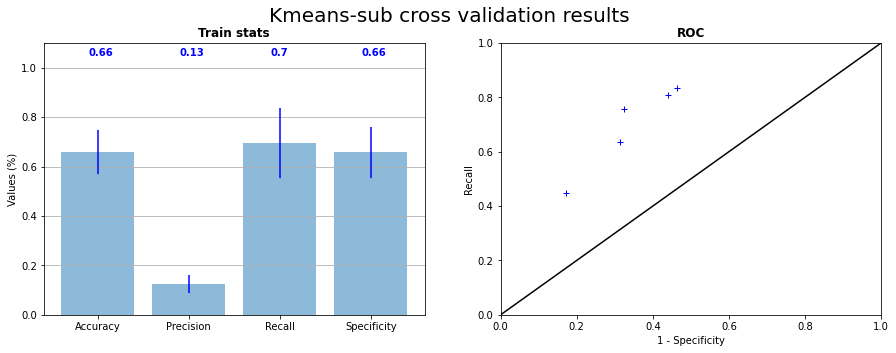
Fig. 3.14 K-means on subdataset cross validation on the 5 samples statistics and corresponding ROC curve#
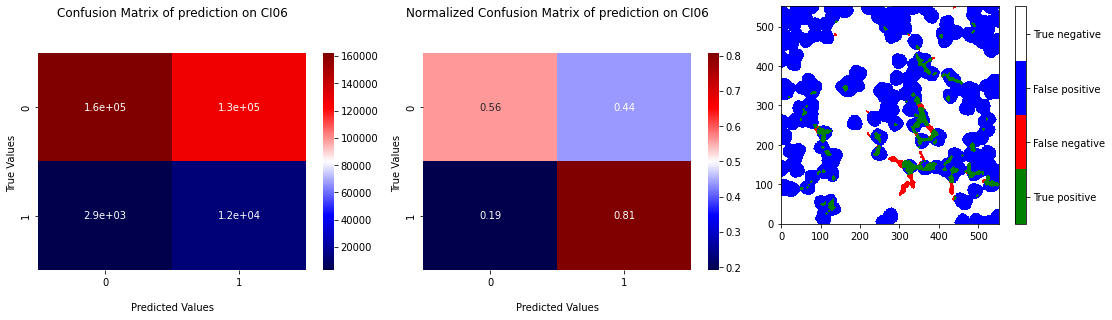
Fig. 3.15 Confusion matrix of prediction of Kmeans on CI06 with learning on the subdataset of the 4 others samples with projection of the prediction.#
3.2.3. Support Vector Machine#
The Support Vector Machine (SVM) classifier is a popular method of classification that search to calculate the best decision function able to segregate the categories of the dataset. A multitude of parameters can be modified to fit at the best to the data, in particular the kernel used to calculate the decision function, characterizing the form of this function (linear, polynomial, non-linear,…). In our case, we chose to use the kernel Radial Basis Function (RBF), allowing to build a function relative to the distance between individuals.
The computation cost of SVM is high in high dimensions. We choose to apply undersampling on data before learning with SVM to reduce this cost. The Figure 3.16 presents the results of the cross validation and the position of test on the ROC curve and the Figure 3.17 the confusion matrix and the projection of the prediction for the test on CI06. We can see that the majority of the RX points are caught by the predictor with a prediction area less linked to grain boundaries. The false positive rate is however high (mean \(40 \%\)).
SVM allow also to apply weights on observations to modify the cost of a mistake of classification. We make several cross validation, variating the weight of the mistake on class RX. The mean positions of these cross validations are presented with their standard deviation on Figure 3.18. We choose to keep the weight of \(0.65\) for class RX as the best model to keep a maximum of specificity.
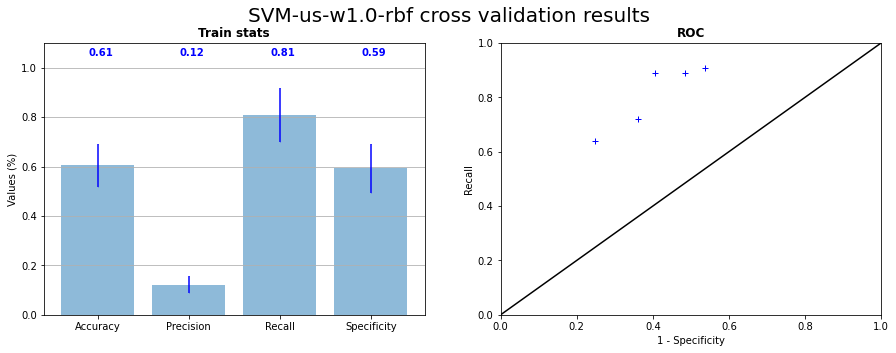
Fig. 3.16 SVM RBF kernel cross validation with undersampling on the 5 samples statistics and corresponding ROC curve#
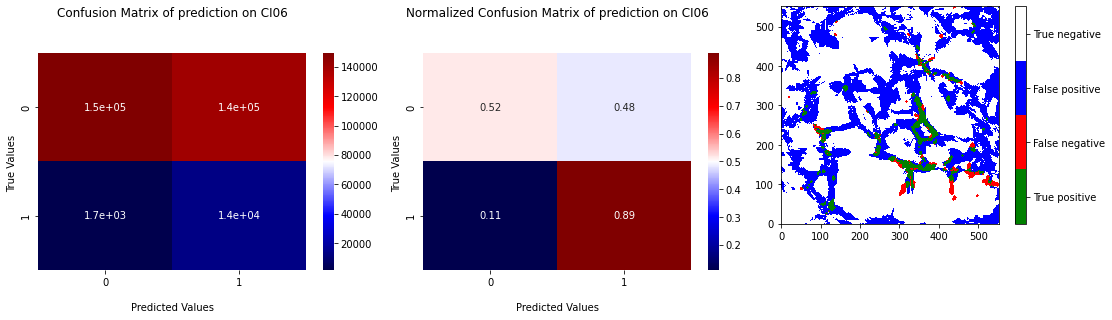
Fig. 3.17 Confusion matrix of prediction of SVM on CI06 with learning on the 4 others samples with undersampling and projection of the prediction.#
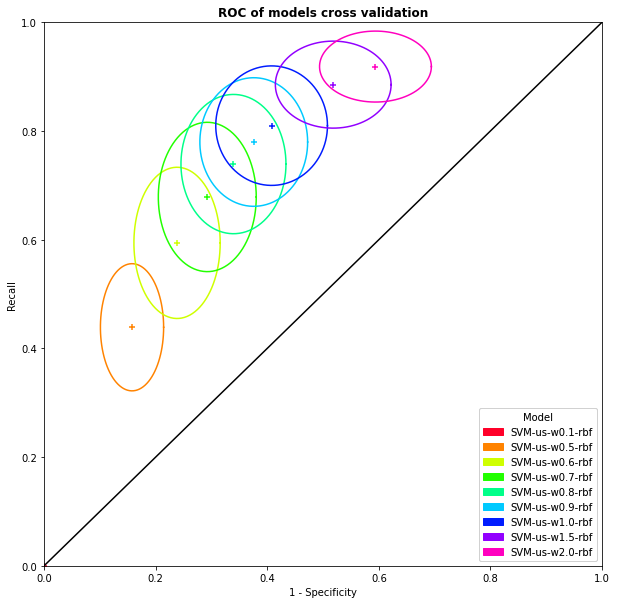
Fig. 3.18 ROC curve with mean coordinates and standard deviation of the cross validation results in function of the weight on the RX category.#
SVM has also a probabilistic version of the classifier. Instead of predicting a label, the predictor gives a probability to be of in a category for each text observation. The Figure 3.19 shows the probabilities calculated by SVM for CI06 with learning on the 4 other samples. We can see that the form of the prediction is almost the same as the Figure 3.17. By threshold on probabilities we can get labels, but we did not get better results that classical SVM has already given.
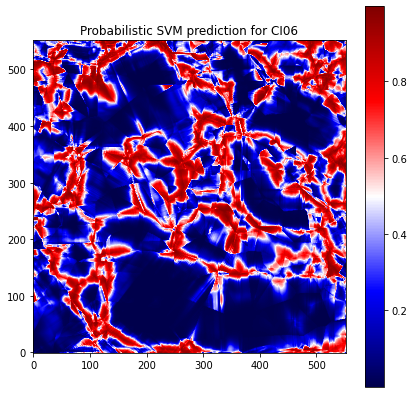
Fig. 3.19 Probabilistic SVM prediction for CI06 with learning on the 4 other samples with undersampling and class weight of RX = 0.65#