
Tree Based Classifiers
Contents
3.1. Tree Based Classifiers#
Common classification methods are based on a decision tree (see Machine learning tools). We first applied to the pixel dataset tree based algorithms.
3.1.1. Random forest#
Random forest (RF) algorithm is a tree based classification algorithm proposed by [Breiman, 2001]. The principle is to generate several decision trees from a double random sample on observation (pixels here) and variable. The final decision tree is determined by the vote of all trees. This method is popular due to the simplicity of use and comprehension. RF has also a reduced computational cost, because compute the solution of several simple decision trees with few observations is easier than compute the solution of one big tree.
RF is the first classification algorithm that we used in the pixel dataset. The Figure 3.1 presents the results of the cross validation method which consists to train the model successively on 4 fold (here our pictures) and test on the last fold and repeat ttesting on every picture with a earning on others. We can also see in Figure 3.1 the ROC curve where the 5 points of the tests have been placed. We can see that the position of points on ROC curve, referring to recall and specificity (see Classification evaluation), are next to left down corner that involve that model predict exclusively \(0\) labels. In other words, RF tents to predict only zeros because of the similarity of all observations (see PCA on pixels dataset). The accuracy score is high because of the high majority of zeros in the dataset. The Figure 3.2 represents the confusion matrix and the normalized confusion matrix corresponding to the test on the sample CI04 and also the projection of the prediction on the picture of true labels. This last one confirm that RF predict only zeros.
After these results, we knew that we will have to use more powerful algorithms to find a good classification. We tried to use the Gradient boost classifier which applies a gradient descent to find the solution of a random forest like algorithm, but the results were similar to random forest if not worse.
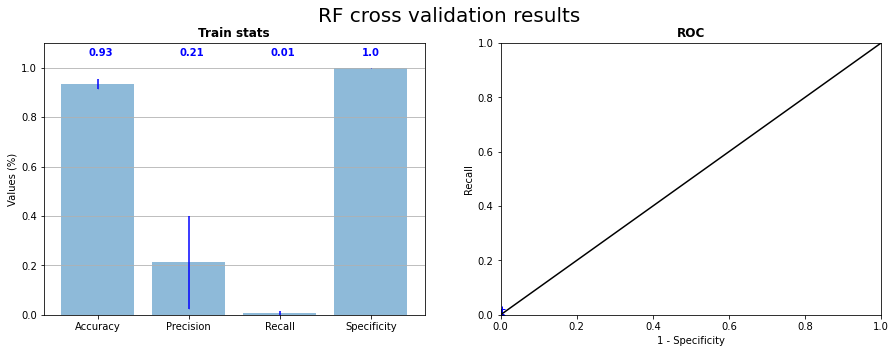

Fig. 3.1 Random forest cross validation on the 5 samples statistics and corresponding ROC curve#
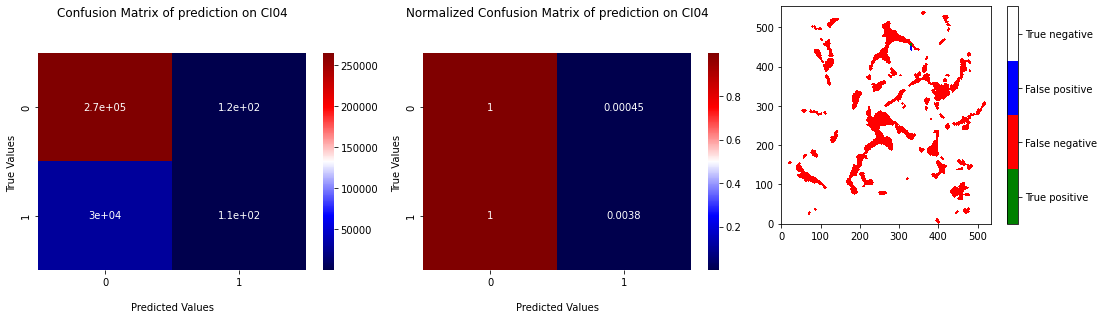
Fig. 3.2 Confusion matrix of prediction of RF on CI04 with learning on 4 others samples with projection of the prediction.#
3.1.2. Extreme Gradient Boosting#
Extreme Gradient Boosting (XGB) is another type of tree based algorithm which apply a gradient descent to find the best decision tree corresponding to data proposed by [Chen and Guestrin, 2016]. We used it to involve the results of RF and keep a tree based algorithm. Due to the high speed of computation of the XGB method, we have tested more combination of parameters and some data selection.
The Figure 3.3 presents the learning statistics of the cross validation with XGB and the corresponding ROC curve. We can see that compared to the Figure 3.1, points on ROC curve are a little bit detached from the down left corner. The global result remains not good but is better that RF result. The Figure 3.4 representing the confusion matrix and the projection of prediction on CI04 confirms that the prediction remains weak.
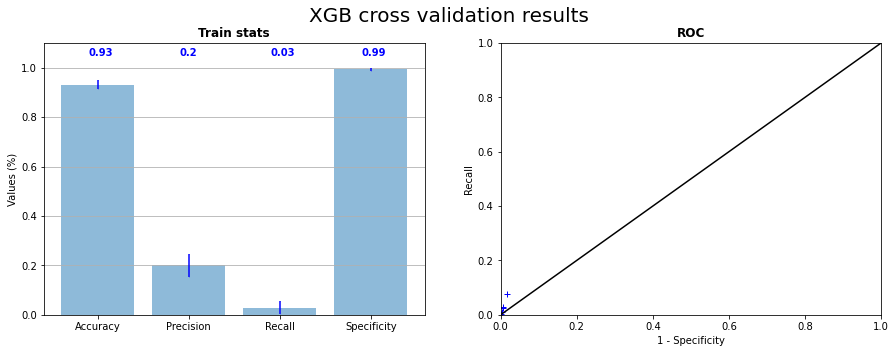
Fig. 3.3 X Gradient Boost cross validation on the 5 samples statistics and corresponding ROC curve#
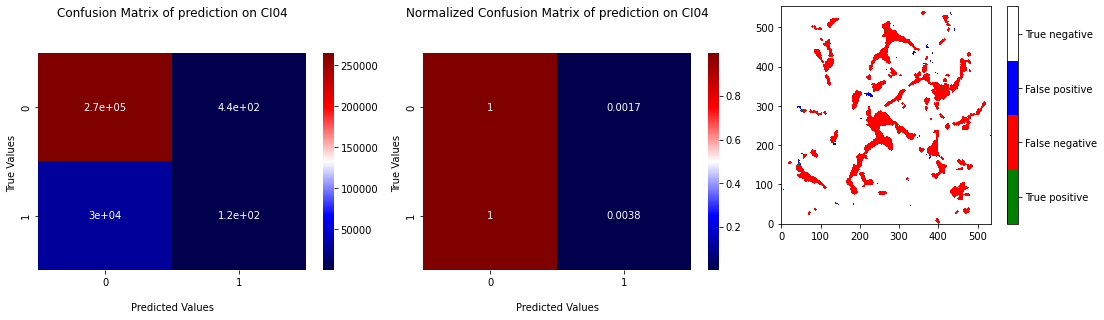
Fig. 3.4 Confusion matrix of prediction of XGB on CI04 with learning on 4 others samples with projection of the prediction.#
3.1.3. Balancing dataset : Oversampling and Undersampling#
Dataset being hard unbalanced (\(4\) to \(10 \%\) of \(1\)), the cost to make a classification mistake on an observation labeled as RX is low compared to the cost to miss many 0. Algorithms have then a trend to choose to minimize the errors on the larger category. To go around this problem, several options are possible. We choose to do first oversampling and undersampling on the pixel dataset. The idea of these methods is to increase the number of observations of the minority class by duplication or reduce the number of observations of the majority class by sampling. Both methods gives at the end balanced sample from the initial dataset. The Figure 3.5 represents theses methods by a schema. Using undersampling may lose part of the information of the majority class when oversampling can lead to overfitting. That’s why this kind of method is to use with precausion.
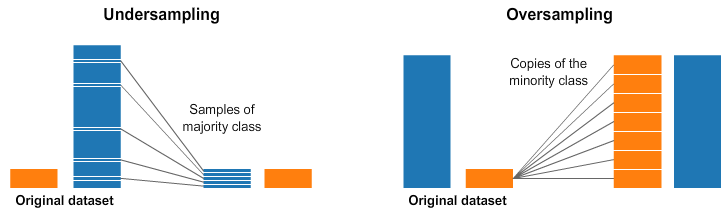
Fig. 3.5 Representation of undersampling and oversampling#
Using undersampling and oversampling allows us to get better results with XGB as show Figure 3.6, Figure 3.7, Figure 3.8 and Figure 3.9. We can see on cross validation results that recall is becoming high until it is not more than \(20 \%\). With balanced data, XGB seams to be able to not predict \(0\) for every observation, but it is still a weak prediction. Undersampling has a little bit better results, but there are not as much stable as results of oversampling, due to the random sampling of the majority class.
In the next parts, we used again the undersampling to reduce the size of the dataset which is too large for some algorithms and induce a very long computation time. Tree based methods haven’t given us convincing results so we decided to apply other kind of algorithm to try to get better (see Neighbourhood based classifiers)
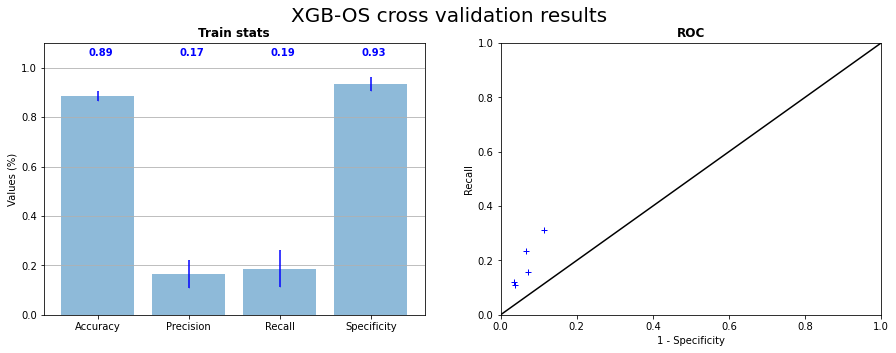
Fig. 3.6 X Gradient Boost cross validation with oversampling on the 5 samples statistics and corresponding ROC curve#
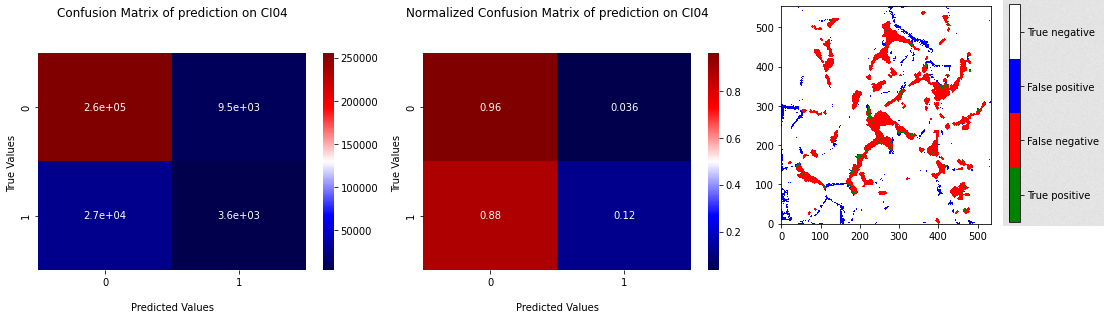
Fig. 3.7 Confusion matrix of prediction of XGB on CI04 with learning with oversampling on 4 others samples with projection of the prediction.#
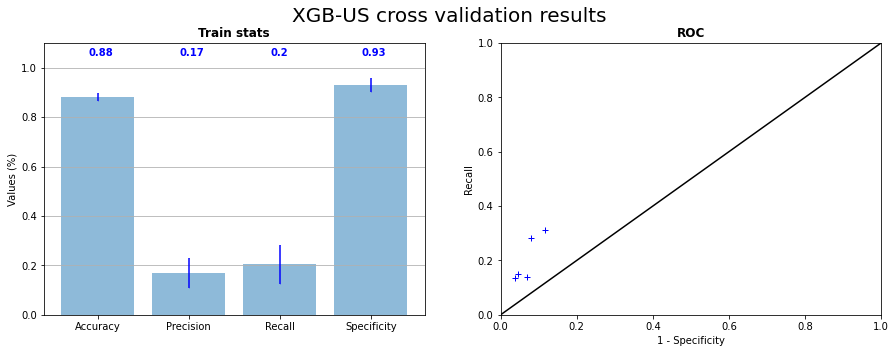
Fig. 3.8 X Gradient Boost cross validation with undersampling on the 5 samples statistics and corresponding ROC curve#
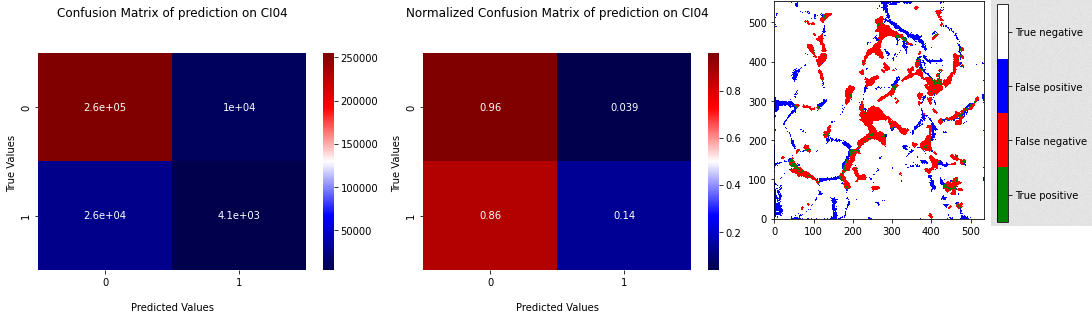
Fig. 3.9 Confusion matrix of prediction of XGB on CI04 with learning with undersampling on 4 others samples with projection of the prediction.#